Neocambria
Humans in the post-ASI world
June 30, 2025
Unless you believe the premise that there is something metaphysical about the general nature of human intelligence, there is nothing stopping us from engineering an intelligence superior to our own.
We've long since built machines far more physically capable than humans.
We have machines that can lift weights far beyond human capability (BelAZ 75710 truck, Liebherr LR 13000, Bagger 293…), that can unshackle from the gravitational pull and go supersonic (SR-71 Blackbird, Concorde…), that can dive miles beneath the ocean's surface (Deepsea Challenger, Project 941 Akula submarines…), that can leave Earth's orbit and head for the stars (Voyager probes, Starship…), or orbit around the Earth for many years (ISS, Starlink…).
We've engineered sensors that stretch the boundaries of perception itself.
With LIGO, we can detect ripples in spacetime—gravitational waves—triggered by black hole collisions over a billion light-years away. Using IceCube, a cubic kilometer of ice buried in Antarctica, we can sense elusive neutrino particles that pass straight through entire planets. Our instruments span the full electromagnetic spectrum: from radio telescopes that capture long-wavelength signals to gamma-ray detectors that see the universe's most energetic events—far beyond the narrow 380-700 nm band visible to the human eye. We've also built detectors that reveal invisible ionizing radiation—alpha, beta, and gamma particles—using tools like Geiger counters.
Just as we've extended our muscles and senses with steel and silicon, we now stand poised not merely to extend, but to surpass our own cognition.
Engineering general intelligence (AGI) is the new frontier.
But what exactly do I mean by AGI (artificial general intelligence)?
There are hundreds of definitions with varying levels of formality, but most boil down to two camps: one that's useful but informal, and one that's formal but not especially helpful.
Here is a formal definition from Legg & Hutter's Universal Intelligence: A Definition of Machine Intelligence [1] paper:
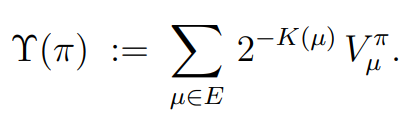
Roughly: compute the above score for your AI agent and once it crosses the "human score" (e.g. median human's score) you have an AGI.
It's not particularly useful because it relies on an infinite sum over all environments of interest, weighted by an incomputable Kolmogorov complexity function. Elegant, but impractical.
A useful, informal definition (inspired by OpenAI's definition [2]) goes like this: we've achieved AGI once we have an intelligence that's useful across a broad set of economically valuable tasks.
How do we define useful?
-> Customers are willing to pay for that AI system/agent's services because it performs those tasks on par with human experts. :)
We could also define AGI in terms of its economic impact—for example, by tying it to global GDP growth (e.g. "we've built AGI once we see 10% annual global GDP growth"). But structural bottlenecks—societal (e.g., resistance to adoption), physical (e.g., shortage of humanoid robots), and others—might still prevent that from happening, even after AGI is achieved.
As a natural extension, artificial superintelligence (ASI) is defined as being strictly Pareto-dominant over humans across all economically relevant tasks.
We already have datapoints of artificial superintelligence (ASI) in narrow, constrained domains—games being a notable example. DeepMind's AlphaGo family of models is a well-known case, built to master Go, a complex strategic board game originating from China.
AlphaGo began with imitation learning from human gameplay (much like how infants first learn), training on hundreds of thousands of expert games (~30 million moves in total [3]).
The next iterations in the AlphaGo family—AlphaGo Zero, AlphaZero and MuZero in particular—eliminated human gameplay data entirely, allowing the systems to learn from first principles using only the reward signal and the environment (i.e., the rules of the game).
Through self-play—and a massive amount of compute—the first Go superintelligence emerged.
AlphaGo's unexpected creativity took Lee Sedol—and the global Go community—by surprise. The now-legendary "Move 37" [4] entered the history books.
Subsequently, AlphaGo Zero defeated the original AlphaGo 100-0 [5]! And AlphaZero and MuZero took it even further—generalizing beyond Go to master chess and shogi (AlphaZero) and extending to Atari games as well (MuZero).
This happened nearly a decade ago (back in 2016), and for years afterward, there seemed to be no clear path to achieving that level of superintelligence in open-ended, world-like environments—given their immense complexity.
Until recently—when we discovered Generative Pretraining of Transformers (GPT) [6], a particular model class trained to predict the next word in a sentence (i.e., language modeling objective) across tens of trillions of words from the internet.
The GPT family was born when Alec Radford pushed the scale of the transformer architecture beyond what Vaswani et al. had originally demonstrated in their seminal Attention Is All You Need paper [7].
It all boils down to two core ideas (The Bitter Lesson [8] was truly prescient):
- Use a hardware-friendly model architecture—one that is highly parallelizable (the transformer). This yields a strong scaling curve (with a steep slope), and remarkably, we've needed only minor architectural tweaks since 2017.
- Scale ad infinitum—data, parameters, compute. The scaling laws (Kaplan et al. [9]) and follow-ups like the Chinchilla paper [10] formalized this intuition.
My intuition for why this works is the following:
- I'll skip the mathematical rigor and keep it simple. As the number of parameters in your transformer goes to infinity, the probability of getting stuck in a strict local optimum — a point where the loss increases in every direction — drops to zero. Take a 1-trillion-parameter LLM (not hypothetical — GPT-4 reportedly had ~1.8T). You're doing gradient descent in a trillion-dimensional space. For a point to be a strict local optimum, the loss must curve upward along every single dimension. Assume the probability that the loss increases along any one direction is p. Then the chance it increases along all directions (under simplifying assumptions) is roughly p¹⁰⁰⁰⁰⁰⁰⁰⁰⁰⁰⁰⁰ (i.e., p raised to 1 trillion). Even if p = 0.999, this evaluates to essentially zero. Consequently, gradient-based optimization is overwhelmingly unlikely to terminate in a spurious local minimum; instead it almost surely lands in wide basins separated by saddle points, which dominate high-dimensional landscapes. The loss keeps going down! :)
- The world model emerges from next-token prediction. I really liked Ilya Sutskever's example here: Imagine a 100-page crime novel. After a complex plot, on the very last page, the detective gathers everyone and says, “I know who the murderer is. The murderer is _.” How do you maximize the probability of that final token (or equivalently, minimize the loss)? You do it by understanding the entire story that came before. You have to grok the characters, the relationships, the clues — everything. In other words, you have to build a world model. The world model is not explicitly trained — it emerges as a byproduct of the prediction objective.
Today, we pretrain our large language models (LLMs), with trillions of parameters, on tens of trillions of multimodal tokens (both human and synthetic). Then, during post-training, we teach them to follow instructions (via imitation learning) and to align with the "median human preference" (via RLHF—reinforcement learning from human feedback).
This was the new AlphaGo moment—Proto-AGI, if you will.
The problem is, imitation learning from the internet can only take us so far—it can match human capability, but not surpass it. At best, it gets us to AGI. So how do we reach the AlphaZero moment for real-world, open-ended intelligence?
We need an equivalent of self-play—and some sort of reward mechanism—for the open-ended world.
As OpenAI's Noam Brown (who works on reasoning models like o3) pointed out [11], self-play converges to a minimax equilibrium in two-player zero-sum games like Go and chess—where that outcome is ideal. But in general-sum, multiplayer environments, that same (self-play) policy breaks down and fails to generalize.
This is where RLVR—reinforcement learning from verifiable rewards—enters the picture. It's the approach behind models like o1, o3, and DeepSeek R1.
The idea is to create RL environments where outputs can be easily evaluated against ground truth. Domains like mathematics (where you can compare against the correct answer), and programming (where you can check against test cases) are ideal.
Reward model traces that lead to correct solutions; penalize those that don't. It turns out this setup is quite powerful—various cognitive and metacognitive skills, such as self-verification, backtracking, planning, and more, begin to emerge in LLMs.
The field has evolved from a "scale only data, parameters, and compute" paradigm to one that also scales the quantity and diversity of RL environments—and it's already showing incredible promise.
We seem to be going from "Yann LeCun's world":

to an entirely new one as described by OpenAI's Dan Roberts in his recent talk [12]:

The Welcome to the Era of Experience [13] paper by David Silver and Rich Sutton goes a step further - proposing to drop pretraining (i.e. imitation learning) altogether and train solely through RL. Not surprising, given that David led the AlphaGo project.
In theory that sounds promising—and with infinite compute, it would likely outperform models biased by human language. But in practice (finite compute regime :) ), it may simply be too inefficient for today's hardware.
The idea is to let LLMs evolve their own internal language (since human language is by no means optimal) as long as they can ultimately solve arbitrary problems. If a model can solve cancer, do we even care how it thinks?
Well, we certainly should—for reasons of safety, alignment, and interpretability. But if the choice is between an alien artifact that cures cancer (but we don't understand it) and a familiar one that can't… we might just take the risk.
In a similar vein, a recent paper from Meta—Training Large Language Models to Reason in a Continuous Latent Space [14]—modifies the LLM to output latent tokens directly, skipping the decoding step into human language. As long as it can ultimately solve the problem, that might be good enough.
These new research directions seem like an incredibly promising path to ASI. Combined with geopolitical dynamics involving China, massive capital investment into ever-larger compute clusters (on the order of millions of GPUs [15]), and a growing concentration of talent in the field—we might get there sooner than most expect.
Some people are bullish, believing we'll reach ASI by 2027 [16]. My estimate falls between 2027 and 2030, with the highest likelihood somewhere in the middle.
The list of "machines can never do X" has been shrinking for centuries. From Ada Lovelace's objection [17] "The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform" to Gary Marcus's [18], and I'm paraphrasing, "AI is dumb—it can't even draw a horse riding an astronaut" we've now reached: "Well, sure, but can it get a gold medal at the IOI? Is it even AGI?" [19]
Even if you believe human intelligence has some kind of metaphysical quality, it seems we're getting closer to engineering it. But on the flip side—how much understanding and intelligence do humans truly possess?
Note: The following subsections reflect my current understanding of reality, along with a fair amount of speculation. Strong opinions, loosely held.
Human understanding is local—much like in the Chinese Room Argument
Do we truly understand? Or are we merely experiencing the illusion of understanding?
When we stub our pinky toe against a wall, it feels as though the pain is located in the toe itself. But in reality, the sensation is generated in the brain—the mind simply creates the illusion and projects the pain back onto the physical location where the impact occurred.
When a person loses a limb, they often still feel sensations, sometimes even pain, as if the missing part were still there. This phenomenon, known as phantom limb pain, is another striking example of the brain generating and projecting bodily experiences.
If there are no retinal cells at the point where the optic nerve exits the eye—our so-called blind spot—why don't we notice a hole in our vision? The brain doesn't just leave it blank; instead, it inpaints the missing information by filling in the gap using surrounding visual cues. Once again, perception isn't a direct feed from reality—it's a constructed experience, patched together by the brain to create a seamless illusion of completeness.
Ever since I read Alan Turing's seminal paper Computing Machinery and Intelligence [20] followed by John Searle's Chinese Room Argument [21], I've been struck by how closely the latter mirrors what I believe is the nature of human understanding. Rather than refuting machine intelligence, it seemed to describe us.
I believe the illusion of understanding arises from the magical performance of System 1 thinking being interpreted—and often misinterpreted—by a puzzled System 2 [22].
Neurons clearly aren't intelligent. They don't understand language.
And when we zoom out beyond the individual neuron, there's still no true understanding in System 1. It's just neural blobs performing classification, and pattern matching. Complex functions living in high-dimensional space, optimized by the evolutionary processes.
So the understanding should then reside in System 2?
But understanding always seems to be constrained to local computations—like that of the human in the Chinese Room.
We don't truly understand how our own body works—it's far too complex of a system. What we do understand is how to drive it, with varying degrees of success. If I want to grab an apple from the table, all I have to do is set a mental objective—fetch that object—and the rest unfolds automagically through neural circuitry I don't understand.
Nor do we understand how neural networks work—biological or artificial. We know how to make useful functions emerge through gradient descent and the right data, but we don't really understand what's going on inside those functions. That's the challenge mechinterp researchers are trying to tackle.
Going beyond the individual, we don't understand how large companies work. Take Alphabet, for example. It's too complex for any single human to truly comprehend, including Sundar Pichai. He operates with a low-resolution view across a broad range of areas. One could argue that while Alphabet's employees collectively run the company, none of them truly understand it. They don't grasp the full system—they just know how to drive their part of it.
And of course, we don't truly understand how the economy works, a vast, dynamic graph of superorganisms we call companies, and individuals acting within them.
Our understanding feels like an illusion—much like phantom limb pain or our failure to notice the blind spot in our vision.
Do we truly understand, or do we just feel like we do? I believe it's the latter.
Humans are carbon-based biological pattern-matching machines
Introduce a third copy of chromosome 21 instead of the usual two, a glitch in the matrix, and you get Down syndrome [23].
Mute the body's response to growth signals and you get growth hormone deficiency (GHD) [24], leaving adults with childlike proportions.
With Hutchinson-Gilford Progeria Syndrome [25], it's the opposite—the body speeds through aging, as if someone hit fast-forward on the biological timeline.
Each disorder is a bug report from our wetware—proof that underneath it all, we're all just biological machines.
I remember watching the sci-fi movie A.I. Artificial Intelligence as a kid, where a boy eventually discovers he's actually a robot. That idea really unsettled me. Imagine living your whole life thinking you're human, deeply believing and feeling as one—only to find out you're just a machine.
But are we really so different from the hosts in Westworld, or from David in A.I. Artificial Intelligence? Or is it merely a difference in substrate—biological versus silicon?
We tend to overestimate the average human's intelligence
A few weeks ago, while riding toward San Francisco, my Uber driver gave me what he called a "difficult puzzle." With pride in his voice, he said it had taken him 30 minutes to solve. The puzzle? "What's the square root of 0.1?"
I gave him a symbolic answer: "1 divided by square root of 10". He shook his head—"That's not the answer." Realizing he was looking for a non-symbolic answer, I said, "1 divided by roughly 3.33" and he lit up: "That's it!".
In return, I gave him a logic puzzle that required no domain-specific knowledge—no need to understand what a square root is, or even what a fraction means.
After 5-10 minutes, he gave up.
Notably, the confounding factor might have been grit—he may have had the intelligence to solve the problem, but he "terminated with an EOS token" before reaching a solution.
In general, I don't think most people have truly internalized the shape of the IQ bell curve. We tend to surround ourselves with a very narrow slice of it. We forget that half of the population scores below the median on that bell curve.
LLMs display jagged intelligence—and so do humans
Jagged intelligence is a coinage introduced by Andrej Karpathy in one of his banger tweets [26]:
Jagged Intelligence—The word I came up with to describe the (strange, unintuitive) fact that state of the art LLMs can both perform extremely impressive tasks (e.g. solve complex math problems) while simultaneously struggle with some very dumb problems…
Chess provides a compelling case study of jagged intelligence in humans.
For generations, world champions have been held up as icons of extraordinary intellect, yet their brilliance is highly spiky/jagged. It's possible for a grandmaster to sit in a hall, cover their eyes, and keep track of dozens of games at once. The current record [27] is 48 simultaneous blindfold games, set in 2016, with the grandmaster scoring 35 wins, 7 draws, and 6 losses.
But the more we studied how their minds work, the more it became clear: it's largely pattern matching built on having observed and memorized thousands of games, both their own and those of other masters. What sets them apart is exceptional domain-specific memory.
But that memory doesn't generalize well beyond the chessboard. In fact, studies show [28] that grandmasters' recall advantage disappears entirely when the board is randomized and the familiar structure is removed.
E.g. in the World Championship of Fischer Random Chess, which randomizes the starting position of the pieces on the back rank, Wesley So decisively defeated former (and four-time) World Champion Magnus Carlsen (4 wins, 0 losses, 2 draws) to become the inaugural world Fischer Random Chess champion.
They've overfitted to a benchmark—sound familiar?
Note: None of this is to say that System 2 thinking—deliberate reasoning and planning—doesn't matter. It still plays a crucial role, especially in longer-duration chess variants.
Similar patterns show up elsewhere—for example, elite Rubik's Cube solvers who can solve the standard 3x3x3 cube in just 3.05 seconds [29].
But none of them go on to solve the Poincaré Conjecture à la Grigori Perelman. And conversely, I'm pretty sure Terence Tao isn't one-shotting his way to grandmaster status either.
My goal here isn't to argue that the present-day LLMs are less jagged than humans—only that this same quality exists in us too. But unlike humans, as AI continues to advance at a break-neck pace, its jaggedness will steadily smooth out.
LLMs can extrapolate
Critics often make the argument that LLMs can't extrapolate, that they can only interpolate within their training data and therefore can't possibly generate new scientific breakthroughs.
But that argument seems increasingly moot.
Interpolation at the knowledge level probably won't lead to groundbreaking discoveries. But interpolation at the reasoning level just might.
LLMs could uncover new heuristics for understanding the world by combining existing ones (simple interpolation)—opening up entirely new branches on the tree of knowledge (i.e., extrapolation).
To summarize my claim: interpolation in the reasoning space can look like extrapolation in the knowledge space.
Humans can engineer an Artificial Superintelligence (ASI)
No matter how you look at it:
a) if human intelligence is pristine and mystical -> well, it seems we have found a way to engineer this mystical emergent entity
b) if it's just pattern matching -> turns out we've already built some pretty damn good pattern matchers
The biggest bottlenecks I currently see on the path to ASI are:
- lifelong memory (~READ)
- continuous learning (~WRITE)
- catastrophic-forgetting (~DELETE)
- multi-agent training environments
The first three are prerequisites for a single ASI; the last is for societies of ASIs.
I believe all of these can be solved with more compute, and maybe a few modelling breakthroughs (or by dusting off one of Schmidhuber's papers from the '90s—iykyk).
Here is a highly simplified model I hold. It seems to me that humans primarily collect data and experiences during the day. Some additional data collection happens at night, through mental simulations. Dreams act as generators of synthetic data. During sleep, we initiate fine-tuning runs (brief micro-replays during quiet wakefulness add incremental updates, but the heavy lifting happens overnight). Some memories are consolidated and burned into the neural weights, while others are selectively erased. Catastrophic forgetting isn't a bug—it's a feature.
It's currently just too expensive to fine-tune massive 10-trillion parameter models every single night. To a large extent it's an infra problem. That said, we'll likely need some algorithmic breakthroughs to fully solve it. We still don't fully understand the shape of forgetting during these fine-tuning runs. But I'm optimistic—whether through mechanistic interpretability or sheer scale, we'll eventually figure it out.
As maximum context length approaches infinity and new methods for compressing information emerge (e.g. DeepSeek's new Multi-head Latent Attention (MLA) mechanism [30]), we may eventually solve lifelong memory without relying on external memory structures like vector databases or Neural Turing Machines [31].
Things are accelerating.
xAI is already building Colossus III: >1 million GPUs in a single cluster [32]. Other players (including Chinese companies) are taking notice and closely following suit. This is triggering an unprecedented wave of compute infrastructure buildouts.
Compute is ultimately bottlenecked by two factors: energy input on one end, and the risk of rendering the planet uninhabitable through waste heat on the other. Even if we approach the Landauer limit [33], there are only so many orders of magnitude we can scale before Earth heats up by several degrees—a threshold that's likely catastrophic. Scaling will continue, but the physical limits are real. At least until we become a multiplanetary species and start building planet-scale computers [34].
With media attention and capital pouring in like never before, more bright minds than ever are working on bold new research ideas.
The first signs of superintelligence in open-ended domains have already begun to emerge:
- Models like ChatGPT, Gemini, and Claude are already remarkably powerful and knowledgeable across a wide range of domains.
- OpenAI's o3-based DeepResearch [35] already outperforms most human analysts—and rivals the best.
- OpenAI's Operator [36] isn't quite there yet, but with a few more iterations, we'll have a system that can use a computer as well as most humans.
This is part of a broader trend.
It's obvious to me that the digital AI workforce is coming.
Over the next decade, everyone will have digital team members—from software engineers (with early examples like Cognition's Devin [37]) to hardware and product designers shaping the physical world.
What do humans do in this new world?
In the short term, we augment ourselves. We augment our workforce. We become more efficient.
What about the long term—beyond the Singularity horizon?
Note: What follows ventures into speculative, science-fiction territory— but every step is grounded in established psychology, sociology, game theory, and current scientific understanding.
Neocambria. Humanity Post-Singularity—The Great Variance Explosion.
Definitionally, once we build an ASI, we will have created a system that is in principle Pareto-dominant across practically every task of economic value.
Thus, by definition, "Humans 1.0" can't compete in this new economic reality. Whatever task we choose to compete on, there exists a cheaper, more efficient, and higher-performing silicon-based (embodied) intelligence ready to fulfill it.
The only solution is a human condition variance explosion (see also this related tweet [38])—humanity forks into multiple branches. A new Cambrian event. Neocambria.
Game-theoretically, I believe Homo sapiens diverges into one of a few main branches:
- Humans 1.0—Reversionists. They reject both genetic and biomechatronic upgrades. They opt out of the brand new world, choosing instead a life in deep nature, supported by just enough self-sustaining background technology to ensure a pleasant existence. A near-biblically long, undisturbed life—until the garbage collection (death) is finally invoked. Their version of the promised Eden (or Jannah, Vaikuntha, Tian, Pure Land). All watched over by machines of loving grace [39]. Today's Amish offer a gentle preview.
- Humans 1.5—The Immortals. They embrace germline edits but shun biomechatronic add-ons. Imagine you could detect a disease like diabetes at the embryonic stage of your child—and cure it. Would you? Of course you would (most of us would). Assuming humans aren't cursed by a hard biological version of the No Free Lunch theorem [40]—and there is some evidence they are (see, for example, the Ashkenazi Jewish [41] population that have IQ/health tradeoff)—then why stop at disease prevention? Why not ask enhance vision, stamina, cognitive ability, physical beauty, even lifespan? (Dario Amodei calls it "biological freedom" [42]) And if the genome allows—wings? (Angels, perhaps?)
- Humans 2.0—Cyborgs. Building on the bio-engineered baseline of Humans 1.5, this branch replaces select biological organs and limbs with superior prosthetics, augments the body with advanced materials, and integrates deeply with synthetic sensors. Their augmented sensorium spans infrared, ultraviolet, infrasound, etc. —spectra once invisible to flesh alone.
- Humans 3.0—Homo Astra. Post-biological entities. These beings retain no biological substrate, yet they are the intellectual offspring of organic minds—their lineage traceable to humanity. These superintelligent entities exist as vast, planetary- or even galaxy-scale computational systems. They command self-assembling factories, producing distributed swarms of perfectly aligned machines that can act in the world.
Humans 1.0 were the bootloader for everything that followed. The four branches are just trunk lines; each will ramify into sub-species as technology, access, and culture diverge.
Consider Humans 1.5. If germline editing remains costly, IQ-boosting dynasties will arise beside unmodified households, spawning fresh caste dynamics inside the "Immortals." Game-theoretic outcomes are murky: will high-IQ clans subsidize the rest or harden the divide?
Cyborg 2.0s and post-biological 3.0s wield overwhelming leverage. Do they conquer, curate, or cooperate? 1.0s—living museums—pose no threat; we 0.9s don't extinguish harmless fauna, so a similar détente seems plausible.
But as 1.5+ lineages accelerate and 1.0s forget their own origins, the latter may come to revere the former as gods.
The only path to minimizing conflict is to escape zero sum dynamics.
Expansion is the safety valve.
Climb the Kardashev scale [43].
Build Dyson spheres [44].
Flood the void with compute.
Dilute conflict across the cosmos.
Our destiny lies among the stars. Lunar super-computers, asteroid foundries, interstellar relays.
And ultimately: to learn how it all began…and how it ends.
Open Questions:
- Governance OS? What operating systems handle a multi-species polity?
- Post-scarcity finance?
- Techno-capital markets?
- New laws of physics that are undiscovered as of now?
Get notified when I publish a new post.
References
- Shane Legg & Marcus Hutter, Universal Intelligence: A Definition of Machine Intelligence,https://arxiv.org/abs/0712.3329 (2007).
- “Our structure”,https://openai.com/our-structure/
- David Silver et al, Mastering the game of Go with deep neural networks and tree search,https://www.nature.com/articles/nature16961 (2016).
- “AlphaGo versus Lee Sedol”,https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol
- “AlphaGo Zero: Starting from scratch”,https://deepmind.google/discover/blog/alphago-zero-starting-from-scratch/
- Brown et al, Language Models are Few-Shot Learners,https://arxiv.org/abs/2005.14165 (2020).
- Vaswani et al, Attention Is All You Need,https://arxiv.org/abs/1706.03762 (2017).
- “The Bitter Lesson”,http://www.incompleteideas.net/IncIdeas/BitterLesson.html
- Kaplan et al, Scaling Laws for Neural Language Models,https://arxiv.org/abs/2001.08361 (2020).
- Hoffmann et al, Training Compute-Optimal Large Language Models,https://arxiv.org/abs/2203.15556 (2022).
- “Scaling Test Time Compute to Multi-Agent Civilizations: Noam Brown”,https://www.latent.space/p/noam-brown
- https://x.com/danintheory/status/1920898285142716782
- David Silver, Richard S. Sutton, Welcome to the Era of Experience,https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf (2025).
- Hao et al, Training Large Language Models to Reason in a Continuous Latent Space,https://arxiv.org/abs/2412.06769 (2024).
- https://x.com/elonmusk/status/1830650370336473253
- “AI 2027”,https://ai-2027.com/
- A. M. Turing, Computing Machinery and Intelligence,https://courses.cs.umbc.edu/471/papers/turing.pdf (1950).
- “Horse rides astronaut”,https://garymarcus.substack.com/p/horse-rides-astronaut
- Twitter hivemind :)
- A. M. Turing, Computing Machinery and Intelligence,https://courses.cs.umbc.edu/471/papers/turing.pdf (1950).
- John Searle, The Chinese Room Argument,https://plato.stanford.edu/entries/chinese-room/ (1980).
- “Thinking Fast and Slow”,https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow
- “Down syndrome”,https://en.wikipedia.org/wiki/Down_syndrome
- “Growth hormone deficiency”,https://en.wikipedia.org/wiki/Growth_hormone_deficiency
- “Progeria”,https://en.wikipedia.org/wiki/Progeria
- https://x.com/karpathy/status/1816531576228053133
- “Most simultaneous blindfolded chess games (total games)”,https://www.guinnessworldrecords.com/world-records/72345-most-simultaneous-blindfolded-chess-wins
- Chase & Simon, Perception in Chess,https://www.sciencedirect.com/science/article/abs/pii/0010028573900042 (1973).
- “Xuanyi Geng”,https://www.worldcubeassociation.org/persons/2023GENG02
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model,https://arxiv.org/pdf/2405.04434 (2024).
- Graves et al, Neural Turing Machines,https://arxiv.org/abs/1410.5401 (2014).
- “Elon Musk plans to expand Colossus AI supercomputer tenfold”,https://www.ft.com/content/9c0516cf-dd12-4665-aa22-712de854fe2f
- “Landauer's principle”,https://en.wikipedia.org/wiki/Landauer%27s_principle
- “The Moon Should Be a Computer”,https://www.palladiummag.com/2025/04/18/the-moon-should-be-a-computer/
- “Introducing Deep Research”,https://openai.com/index/introducing-deep-research/
- “Introducing Operator”,https://openai.com/index/introducing-operator/
- “Introducing Devin, the first AI software engineer”,https://cognition.ai/blog/introducing-devin
- https://x.com/karpathy/status/1846448411362709980
- “All Watched Over By Machines Of Loving Grace”,https://allpoetry.com/All-Watched-Over-By-Machines-Of-Loving-Grace
- “No free lunch theorem”,https://en.wikipedia.org/wiki/No_free_lunch_theorem
- “Ashkenazi Jews”,https://en.wikipedia.org/wiki/Ashkenazi_Jews
- “Machines of Loving Grace”,https://www.darioamodei.com/essay/machines-of-loving-grace
- “Kardashev scale”,https://en.wikipedia.org/wiki/Kardashev_scale
- “Dyson sphere”,https://en.wikipedia.org/wiki/Dyson_sphere